The good, the bad and the badass: The five best web crawlers and sitemap generators for SEO

At the coal-face of technical SEO, we are required daily to sift through a significant tonnage of data. We work with some very large and complex sites here at QC towers and without a generous degree of automation in our workflow, we would be scratching for that proverbial black gold with our bloody finger tips.
Having a box full of trusted and well-honed tools (and, of course, the skill with which to apply them) is absolutely essential to being an effective SEO analyst and providing your clients with an effective, comprehensive and agile service.
As a special treat to all my dear yet anonymous readers, I’ll be letting you in on some of my favourite tools in my blog over the coming few months. Today we start with one of the simplest yet most important tools: The Web Crawler.
When beginning an SEO audit on a site for the first time, one of the best jumping-off points is to first get an exhaustive list of crawlable URLs. This is a great place to start for a number of reasons:
- It’s important to have an overview of the site’s URL format and information architecture
- You can begin to spot duplication simply by looking for textual repetition in alphabetically sorted URLs
- Bad smells such as heavily parameterized URLs and keyword dearth can be identified from simply scanning your eyes over the list
- Smaller clients often don’t have XML sitemaps in place or the ability to generate them, and so it can be useful to be able to do that for them
- If you can grab some additional information about each page crawled (such as titles, meta descriptions, HTTP status codes, page size etc) then you can begin to identify and verify a whole range of issues from a single spreadsheet
“But Haitham!”, I hear you cry, “Can’t the client just provide you with a list of URLs from their CMS?”. As it happens, often they cannot for one reason or another. Moreover, if they do happen to be able to provide you with a list of URLs, those will just be the URLs that they believe are on the site; some may be uncrawlable but they haven’t realised it and many more may have been indexed than they realise ever existed.
“But Haitham!”, you wail again, “Can’t you just see a more accurate representation of what URLs have been indexed by Google using the site: operator?”. Well, yes that is a more accurate way of seeing what has been indexed, but you cannot trivially download that list from the search results pages. That means it cannot be sorted, filtered or searched easily, which is where all of your analytical power comes from.
So what’s the best way of going about obtaining this list of URLs? The answer is a web crawler. There are many free and paid-for web crawlers out there that offer a range of advantages and disadvantages each. In my own daily work I use a variety of them, selecting the best tool for the specific task at hand. Below are my five favourites:
GSite Crawler
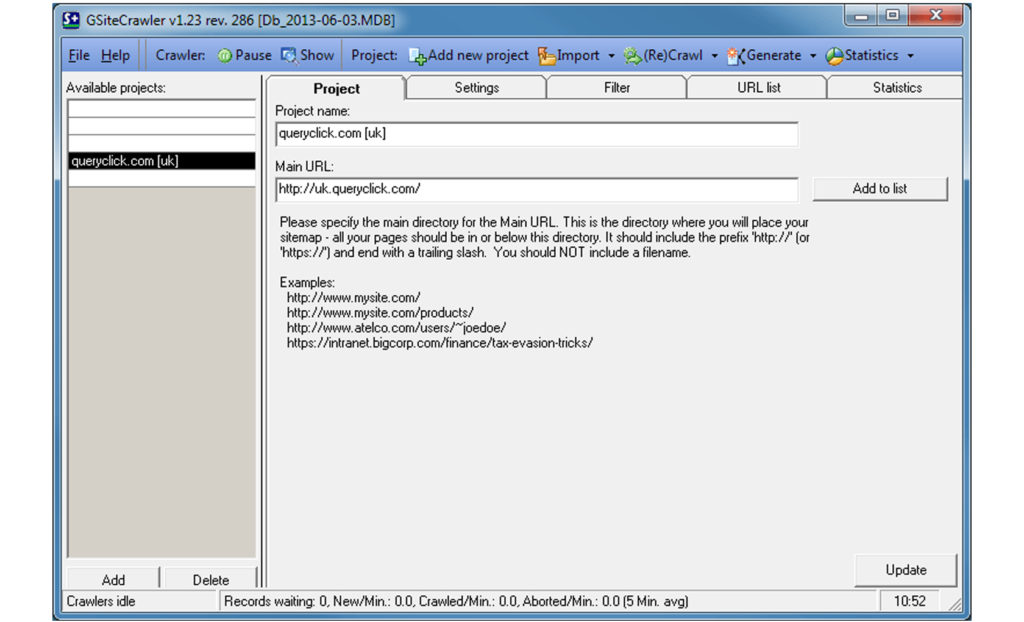
Good Old GSite, as it is affectionately (or otherwise) known in the tech team here at QueryClick, is a work-horse of daily SEO. It is free to use (with a recommended donation) and provides most of the day-to-day functionality that technical SEO requires from a crawler. Combined with the best URL filtering system of all the crawlers in the list, it’s easy to see why this is everyone’s go-to.
The Good:
Firstly, it’s free, which is always nice. Also, GSite has a very convenient way of keeping track of previous crawls, including the discovered URL lists, filters and any other settings, all bundled up into ‘projects’ that are easy to switch between. This is very useful because it allows single-click re-crawling of a site, which you frequently want to do to verify a change made by a developer.
Moreover, one of the strengths of GSite is its configurability. You can very easily set the number of concurrent crawlers and the maximum crawl rate of each (not bringing down a client’s site is something you have to be careful of), the timeout for a page request, the user-agent given when requesting a page and the proxy settings. There are also a large range of options for exporting data, including plain old CSV (various sub-configurations available here), XML sitemaps, txt sitemaps, robots files produced from your filter list and interesting meta-data such as page speed and duplicate content statistics.
The Bad:
GSite is buggy as hell. From minor interface glitches such as the crawled URLs list not populating until you scroll down, to awful hidden errors like the filter randomly ignoring the first entry in your banned-URL pattern list, requiring you to remember to put a dummy pattern in the first space (something that you will invariably forget to do).
There is also the ‘project’ system of maintaining previous crawls that I mentioned before. While this is a useful feature, it relies on GSite’s built-in database model. The database frequently fills up and reaches a seemingly arbitrary maximum size before it refuses to crawl any more. You can try to compress the database using the database-compression feature, but this always seems to throw errors. You can work-around by simply starting a new database, but then you lose the easy access to your old crawl projects.
That’s all without mentioning that the interface is terribly unintuitive too, but that’s something you can learn to live with. GSite hasn’t been updated since 2007, so don’t hold your breath for any fixes any time soon, either.
The Badass:
As I’ve alluded to, the killer feature of GSite is its URL filter. Sites that make use of parameterised URLs (almost all of them) can easily trap spiders in infinite loops or have them crawling thousands of identical pages. Also, sometimes you really do want to exclude certain types of URLs such as anything to do with RSS or any blog URLs.
GSite allows a very easy way to add patterns to the URL filter to prevent any type of URL you want from being crawled. The filter can be changed mid-crawl (after pausing the crawlers) and can be applied to filter the current crawled-URL list and the crawl queue, completely avoiding the need to ever start a crawl again from scratch. The pattern matching type can be set to anything from straightforward sub-string matching, to simple wildcard matching (like robots.txt) or full regex.
Simply put, no other crawler, paid-for or free, can match this filtering power and flexibility.
Screaming Frog SEO Spider
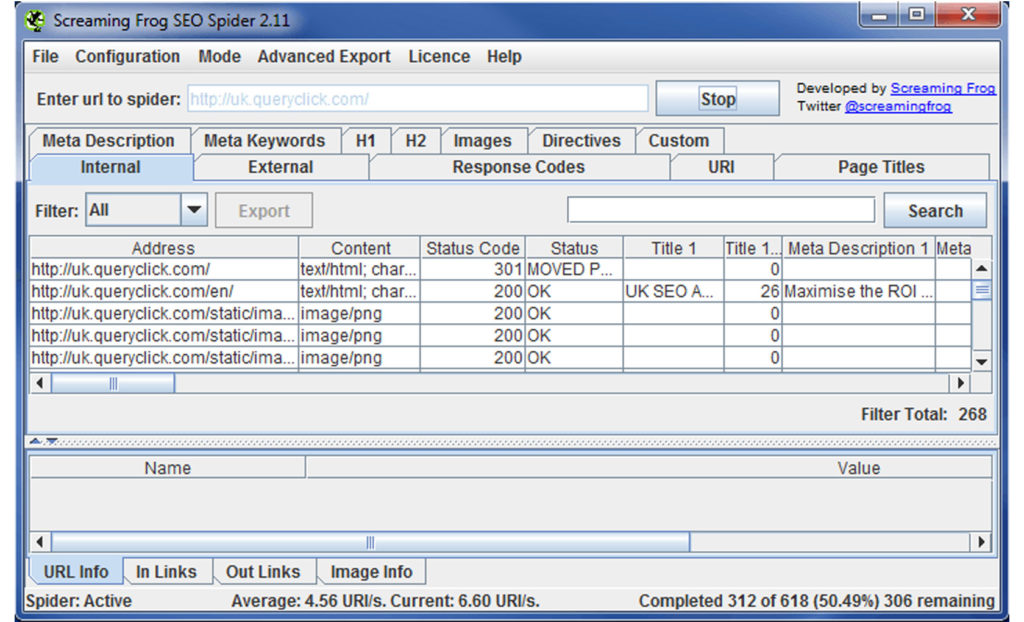
Free trial version downloadable here (can be upgraded to full version with a license purchase)
Screaming frog seems to be the de-facto industry standard for SEO crawlers. Indeed, it even has SEO in the name. As a tool built specifically for SEO, it has some fancy features that you won’t find in your regular web crawlers. As you might expect for a commercially-oriented software tool, Screaming Frog is not free; it costs £99 per year. There is a free trial version, but this is limited to only crawling 500 URLs, making it effectively useless for anything other than getting a flavour of what Screaming Frog can do for you.
The Good:
There are a lot of good things about Screaming Frog, probably too many to cover here. The key selling point is the scraped on-page elements and the meta-data that Screaming Frog will provide along with every crawled URL. While most spiders will get you at least the Page Title and the Meta-Description, Screaming frog will also provide the HTTP status code, header tags, the canonical URLs where they are provided, the page size, the on-page word count and many more bits of data that are super-useful for identifying problems and verifying their resolution.
Another unique and powerful feature is the ability to process a supplied list of URLs, rather than spidering. This is something I frequently have need for, for example when the client provides a list of URLs that they want checked or if I have already filtered a sub-set of URLs from a previous crawl that need re-processing.
Screaming Frog provides a large number of custom export options including only URLs with HTTP status codes in a certain range and images without alt text. This seems useful, but in practice I have never found need for it.
A great positive for Screaming Frog is the support (only available in the subscription version) and regular updates; something that most other crawlers sorely lack.
The Bad:
Screaming Frog uses the utilitarian Java Swing default look-and-feel, which is ugly and dated. Furthermore, because it’s a Java application it can be a bit of a memory hog.
There’s a surprising lack of control over the spider behaviour provided in Screaming Frog, particularly in rate-limiting. You can specify the number of concurrent crawl threads, but you cannot specify the wait time between requests, which could put modest servers under some strain.
Also, the URL filter is lacklustre indeed. If you want to filter URLs, you need to provide a list of regular expressions in a plain text field. This is rather unintuitive for less tech-savvy users and the filter can effectively only be set in advance of a crawl, making it much less useful than GSite’s. There is the much-touted ability to filter by any custom-defined text that appears in the on-page HTML. This is something unique to Screaming Frog, but I’ve personally never found it useful (if only you could scrape a custom-defined element, but what magical tool could possibly allow that?).
The Badass:
A common use-case for crawlers is to verify changes that developers have made to the site. In an ideal world, developers make changes on a staging site and only push live once you, the SEO expert, have had a chance to verify the changes are in line with requirements. Staging sites are often protected by a log-in, and spiders cannot authenticate…. except Screaming Frog.
Being able to accept cookies, authenticate and provide any custom user-agent and crawler-agent make Screaming Frog almost bullet-proof and able to crawl any site. This is the killer feature for me, and the reason any serious SEO analyst should be forking out that £99 a year.
Xenu Link Sleuth
Xenu is a bit of an oddball, as it is not designed as a sitemap generator or specifically for SEO, but for the intention of discovering broken links on a site. This leads to some unusual limitations but also some handy features. Although Xenu may not be designed with SEO in mind (originally written in 1997, it predates the existence of SEO), it gets a lot of traction in the SEO community. Xenu is free and slick, so it’s a good backup to keep handy.
The Good:
The first thing you notice about Xenu is that, because it is written C++, the application is fast and slick, with a low memory footprint (this also means it is only available for Windows, but you may have some luck running it via WINE under Linux or via Crossover on a Mac).
Xenu will provide you with a reasonable, if basic, amount of data from each URL request including simple on-page (title and meta-descriptions), page size, the depth of the page from the root (useful for analysing a site’s information architecture) and the page status. If you set Xenu to treat redirects as an error, then you can also get the redirect status codes.
Ultimately Xenu’s strength, as you would expect from its original design intent, is in discovering and reporting URL errors. More detail is given about errors that any other crawler provides, and Xenu will probe more types of URI than other crawlers to ensure it is comprehensive in its problem-detection
The Bad:
The main problem with Xenu is the lack of configurability. The filter ability is extremely limited and can only be applied at the start of a crawl, the crawl rate cannot be limited (although the number of concurrent threads can be set), the data export options are few and you cannot limit the crawl to only HTML links (CSS, JS, images, PDFs, maito links etc will all be crawled).
The Badass:
It’s hardly going to set the world on fire, but one cool feature of Xenu is the ability to dynamically prioritise URLs as the crawl is in progress, by simply scrolling through the queued URI list. URIs that are currently in the displayed area of the list will be processed next, allowing you to get near-immediate results of particular areas of the website that you might be interested in, rather than having to wait for the full crawl to finish. No other crawler allows any sort of prioritisation that I’m aware of.
WonderWebWare SiteMap Generator
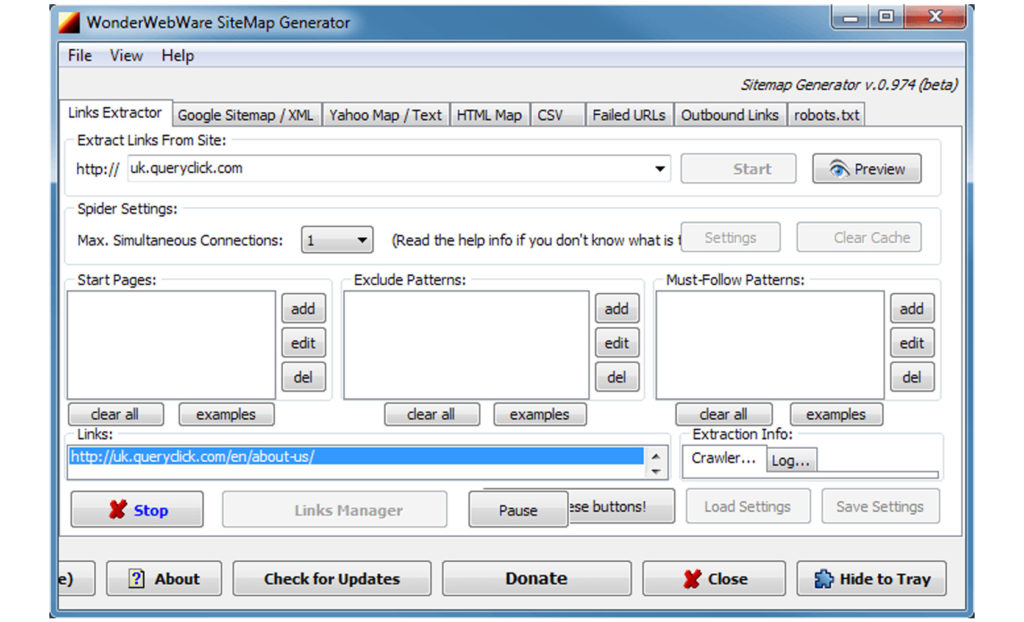
The unimaginatively titled SiteMap Generator is a simple tool that does what it says on the tin. It’s the no-frills option for when you know exactly what you want, and that’s a list of URLs, page titles, meta-descriptions and nothing more. The software is effectively free, although a donation is required to unlock some of the less useful features, although this works on the honour system since you can just click “unlock these buttons” at any time.
The Good:
As a comparatively simple application, the main appeal lies in that simplicity. Starting a crawl is as simple as pasting a URL into the interface and hitting “Start”, then watching all those lovely URLs zip by.
A basic exclude pattern facility is provided, which is frankly better than the Screaming Frog one, as well as a seemingly redundant “Must-Follow Patterns” field, but that’s about it for the main interface.
The Bad:
The most obvious deficiency is the simple lack of data that SiteMap Generator gives you. If you need to find out anything about the URLs you are crawling, including anything on-page, in the HTTP response or any meta-data, you need to be looking somewhere else.
Another annoying problem with SiteMap Generator is its inability to handle characters in the URL outside the ASCII set, whereas it should be handling all UTF-8 encoded characters.
The Badass:
The strongest feature of SiteMap Generator is its clever rate-limiting options. Not only can you specify the minimum time between requests down to the millisecond, you can also tell it to take a break for ever fixed number of requests. For example, you can tell it to make no more than one request every 0.5 seconds and then wait for 5 seconds after every 100 requests. This gives you the flexibility to be gentle enough for even the most piddly web servers but also get a decent throughput.
The QC Spider
Technical SEO is a fast-changing scene. If you want your tools to be ready for every new development, sometimes you have to forge them yourself, and at QC we’ve done exactly that.
Our Super Secret tool allows us more flexibility and precision in our analysis than any off-the-shelf tool could hope to provide and is being molded to fit our exact requirements.
The Good:
I wouldn’t want to give away all of its best features, but as a quick peek at what it can do that the other spider tools cannot:
Some of the spider tools will let you know when spidered URLs are redirected, others may give you the HTTP status code, and Screaming Frog even tells you what the target of the redirection is, but none of them will follow the redirect chain, telling you what each status code and URL rewrite is in turn. The QC spider does exactly this.
One of the most important developments in technical SEO in recent years has been the hreflang tag. Keeping on top of an hreflang deployment across large, mutinational sites can be a difficult task, but the QC spider makes this significantly easier by being able to scrape hreflang tags and their associated URLs, allowing them to be viewed and verified all in one place.
Because the spider is entirely bespoke, it can easily be rate-limited in any fashion we see fit. The spider is built in such a way that it is very easy to isolate and scrape virtually any on-page element with only a few minute’s source modification. This allows us to pull page elements unique to an individual client’s site for custom analysis.
For example, we recently had a client that had removed an element from their footer across the site, but for some reason the change had not propogated to every page. Within just a few clicks and tweaks, we were easily able to crawl their site and identify all pages with the old footer format and have them corrected.
The Bad:
The main negative aspects of working with an in-development tool is obviously that it lacks the polish of a publicly available piece of software. And when I say “polish”, I mean any user interface of any kind. Working with a command-line tool is fast and efficient when you are comfortable with doing so, but it means that it isn’t quite ready for all the account managers to use for themselves.
Another consequence that falls out of using pre-production software is that every now and again you bump into an issue or bug or corner-case that hasn’t been covered. That’s all just part of alpha testing, though, and helps us to build a more robust tool.
The Badass:
The best part of having the QC spider is knowing it will always be kept up to date with the latest developments in technical SEO (unlike GSite), we will always be able to configure it to the job in hand (unlike Xenu), it has all the features we need (unlike SiteMap Generator) and will be free for us to use forever (unlike Screaming Frog).
At the end of the day, your choice of web crawler and sitemap generator boils down to choosing the most appropriate tool for the job. GSite should see you through for most basic things, and Screaming Frog is truly excellent if you’ve got the budget. But there’s really no replacement for being able to do things your own way.
Own your marketing data & simplify your tech stack.
Have you read?
Chrome’s announcement on dropping cookie opt-in last month closed the door on a 5 year saga for marketers. But what is the landscape like in 2025 for cookie-based measurement?

Generative AI is transforming the way that marketers plan and assemble content for their Paid Ads. As big platforms like Google, Meta and TikTok increasingly build the tools needed to...

In a surprising move that has sparked heated debate, Mark Zuckerberg announced on his Instagram that Meta will be reducing its levels of censorship and in particular fact-checking on its...