Using GraphQL for clean API Design

What’s a GraphQL?
At QueryClick, we work with many APIs, including ones to collect and store data. We build our software as microservices and do not directly expose each service unless we need to. However, with QueryClick having a lot of data, we need to be able to conveniently and securely expose it. This could be done through multiple endpoints, but could quickly become unmanageable and lead to comprehensive API documentation, causing a huge learning curve for users of the data (covered more further down). To deal with the data exposure and keep things simple for the end user, we use GraphQL.
GraphQL is a query language for APIs. It was originally developed by Facebook for internal use. But don’t worry, it is open source now!
Facebook open sourced the GraphQL specification in 2015 and can be found on their GitHub.
With Facebook open sourcing their GraphQL specification, it can be used with most programming language. Major GraphQL clients include Apollo Client and Relay. GraphQL servers are available for multiple languages, including Haskell, JavaScript, Python, Ruby, Java, C#, Scala, Go, Elixir, Erlang, PHP, R, and Clojure.
This article is aimed to give a brief overview of why QueryClick decided to use GraphQL, what problems it solves and allow for you to make a decision on if GraphQL is right for you! This isn’t a walkthrough or tutorial on how to create a GraphQL service. However, there are a lot of amazing documentation by GraphQL and my favourite, Apollo (highly recommended if you’re developing with JavaScript).
Schemas
You have probably worked with an API that has countless endpoints, no clear indication of what the data actually looks like, and very poor documentation. Sadly, this can be a common issue across different architectures (REST, SOAP etc).
Fortunately, GraphQL allows for a developer to write schemas.
GraphQL schemas support queries, mutations, subscriptions and more!. A schema is like a blueprint of how we want our data to work/look. A schema makes it easier to understand what data is available and in what format. We’ll create a basic schema to query.
First let’s define our query and schema. We will create a query called `getRestaurants` that will call a type `Restaurant`.

We have created our first query. We define a query named `getRestaurants` that returns a type `Restaurant`. When GraphQL executes this query it will look for the relevant type and resolver to validate the data.
Let’s create that `Restaurant` type:
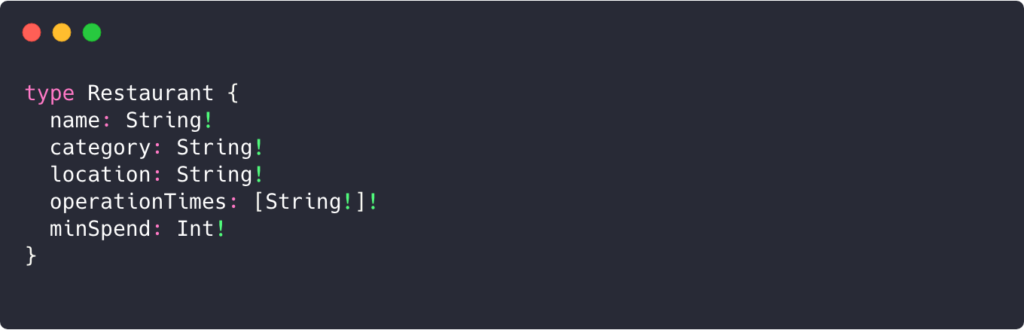
In this example, we are explaining that the type ‘Restaurant’ has these criteria:
- name is required to be a string.
- category is required to be a string.
- location is required to be a string.
- operationTimes is required to be an array of strings.
- minSpend is required to be a signed 32-bit integer.
- The exclamation mark means the field is also non-nullable and the GraphQL service promises to always give a value back when this field is queried.
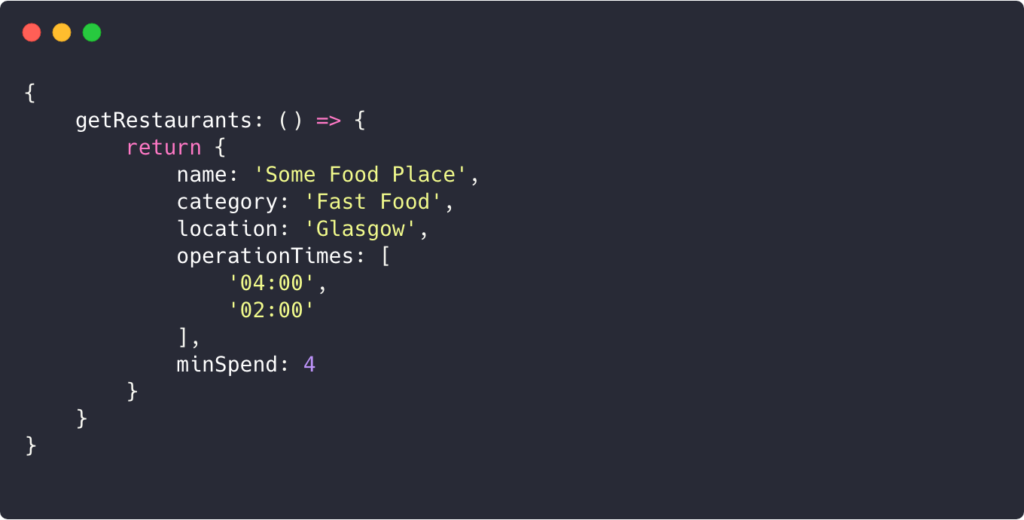
The last thing we need to create is a resolver. We’ll write this part in JavaScript but remember: you can use GraphQL in any backend service that has a supporting library!
What we’re doing here is returning an object to validate against the schema.
GraphQL is strongly typed
When querying an API, you want to know exactly what data you will get back and in what format. If you are asking an API for the price of a certain item and it returns a string, you will probably have issues…
Having a strict contract in place that clearly describes the type of data available is crucial in ensuring your application works as expected. GraphQL services describe their types and validate the query against that schema.
Why GraphQL helps with clean API design
Let’s say we have a client that wants to be in the food delivery service (you know, those insane cyclists ones). There are a few factors to presenting relevant restaurants to a user:
- It needs to be within a certain radius of the user. Let’s say 3 miles.
- The restaurant has to be currently open and accepting order requests.
- Users can search for the type of food they want.
Let’s start building a basic API for this. We will “query” a basic RESTful and GraphQL API to show the different approaches.
To keep the first example simple, let’s assume the API already knows the location of the user and it is within delivery range. And let’s only display 2 restaurants as this could get huge…
RESTful API
Endpoint: /api/restaurants/burgers
Response:
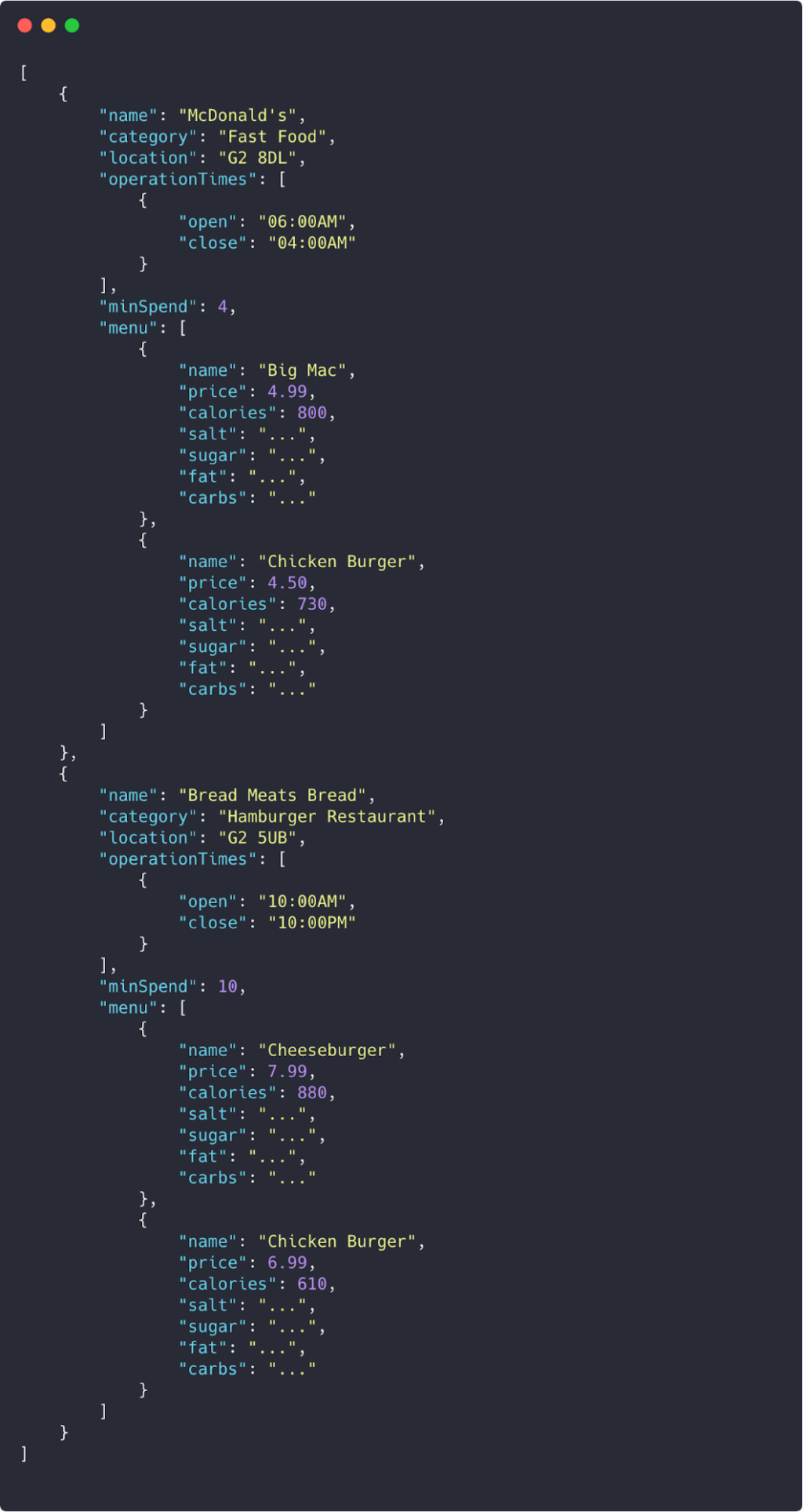
If this was a real-world API, this JSON response could be HUGE (especially in Glasgow given how many burger joints there are…).
The user requested restaurants that sell burgers and this is the response. At this stage of the user journey, the user only needs a list of restaurants that sell burgers in their area and can deliver. The `menu` array would not be used. With a RESTful endpoint, you would get all of this data back, but the frontend developer just wouldn’t use it. In our example, it’s bytes. But If this was a real API, it could be a lot of data (more restaurants, burgers etc…) that just isn’t going to be used. This adds latency and a larger waiting time for the data to come back to the user, especially since we’re dealing with mobile users who may be on a slow 3G connection.
GraphQL API
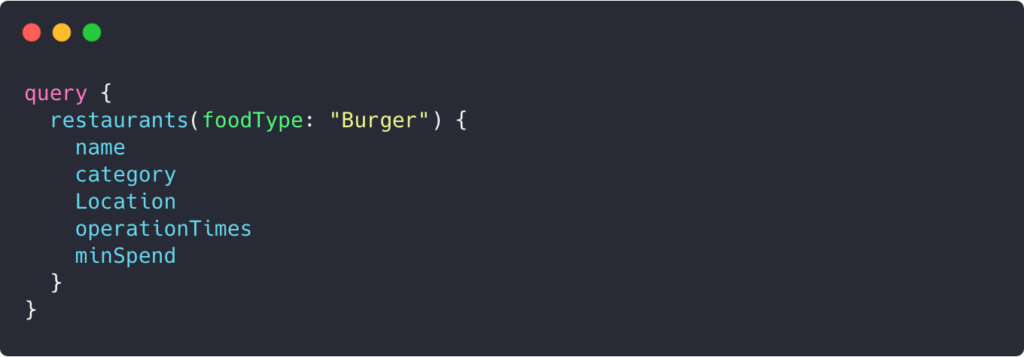
endpoint: /graphql
Query sent to GraphQL:
Response:
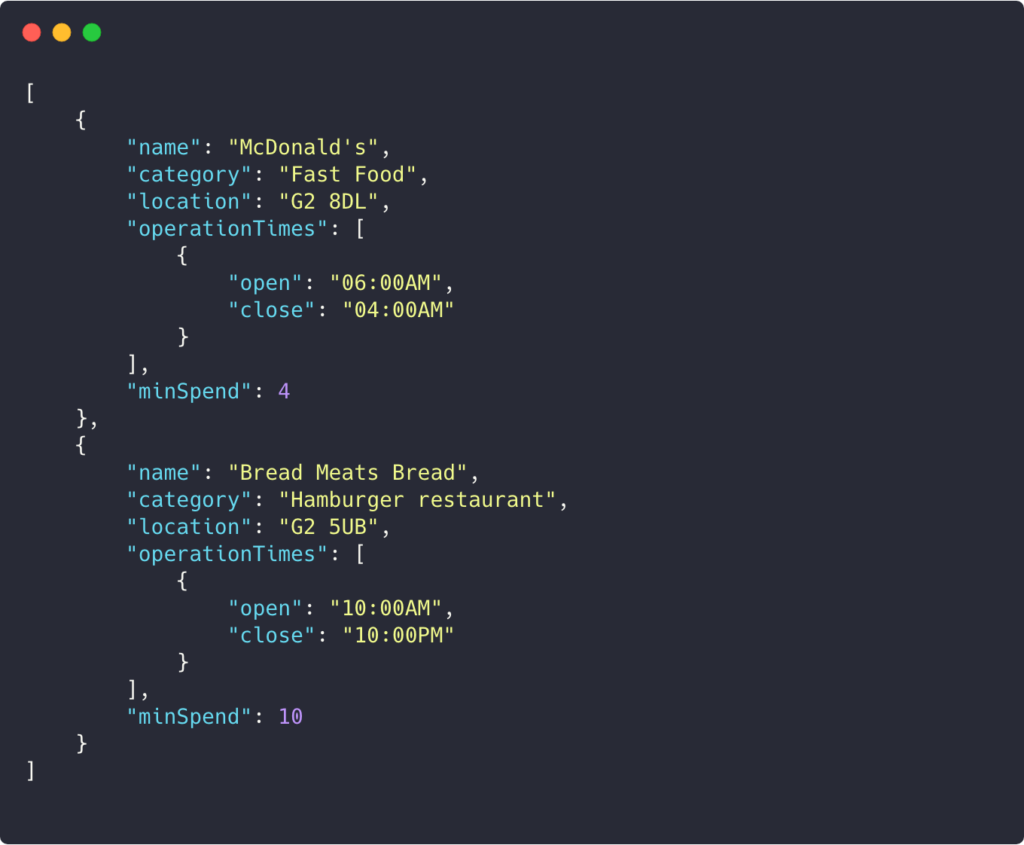
The user still requests restaurants that sell burgers. With the user being at the browsing stage, they don’t care what is on the menu. They just want to know what restaurants are available so they can decide where to eat from. This response is much more concise.
GraphQL will only return what you have asked for – nothing more, nothing less. This means we can get more relevant information with our query and not waste the user’s bandwidth and time!
Now let’s say the API doesn’t know the user’s location but needs it to return relevant restaurants.
RESTful API
endpoint: /api/restaurants/G21/burgers/ (G21 being the user’s location, which would be a parameter on the request)
Now we need a different endpoint to only look for restaurants that sell burgers within delivery range. We could quickly build up a whole list of endpoints for different scenarios that would be hard to maintain, especially if the API needs to be versioned.
We would also still get that huge response containing information the user doesn’t need.
GraphQL API
endpoint: /graphql
Query sent to GraphQL:
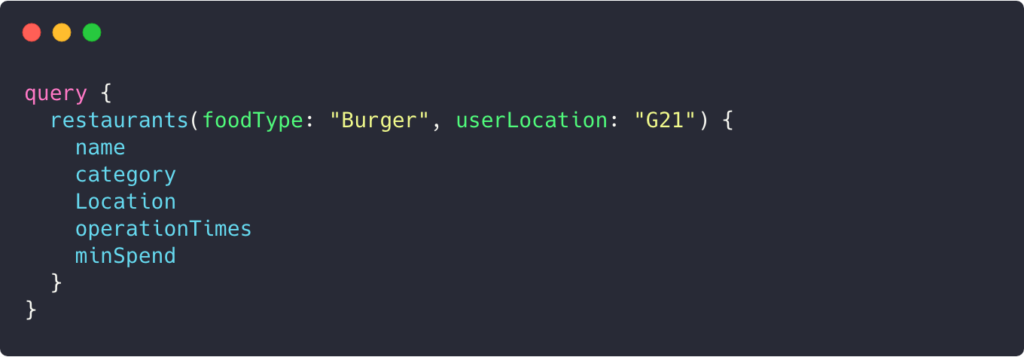
Our GraphQL resolver would query relevant data sources and return the results. Again, nothing more, nothing less than what the GraphQL query asks for.
The user has now selected a restaurant and their food (Bread Meats Bread of course) and is ready to confirm their order. We also need to show progress data on the current state of their order (accepted, being prepared, cooking, out for delivery).
(Let’s not worry about the payment and invoicing service for this example).
There are a few steps in displaying the current state of their order:
- We need to get the order ID for the client when they hit the “track order” page.
- We need to send that order ID to a service that deals with keeping track of the order.
- We then need to return the status back to the user.
RESTful API
First, we need to send a request to get the user’s order ID for this order.
endpoint: /api/orders/1/ (1 being the user ID)
Response:

We then need to take that orderNumber and send a request to check the state of the order.
endpoint: /api/orders/state/215356178 (215356178 being the previously returned orderNumber)
Response:

GraphQL API
endpoint: /graphql
Query sent to GraphQL:

Our GraphQL query `order` will call its resolvers in the backend that will get the order number and then send a request to the endpoint: /api/orders/state/215356178.
Response:

Of course, the RESTful API could have an endpoint for this specific request:
endpoint: /api/orders/1/track (1 being the user ID).
But this would lead to having yet another endpoint and adding much more complexity for the front-end dev team, rather than abstracting it.
GraphQL allows the frontend to be abstracted away from unnecessary API calls and complexity, allowing us to focus on what it actually needs – concise data.
With GraphQL we simplify how a client interacts with our API. Imagine we allowed users to order from their smartwatch where there is even less room to display information and (potentially) greater latency. The data returned should only be what is needed for that specific user and client.
Of course, if two API calls need to be made in order to return data, GraphQL will not magically be able to only make one request; the resolvers will still need to query separate data sources. However, the client will have a much easier job, regardless of what client it is (mobile phone, smartwatch, fridge?).
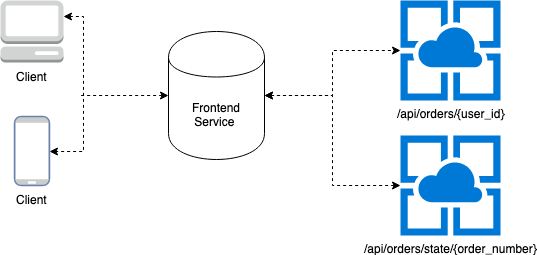
Example RESTful Service Flow
The front-end service would have to query two separate APIs before it can return information to a user. This can be painfully slow if the user has a slow connection. This flow will also return data that will never be used at the stage of listing restaurants.
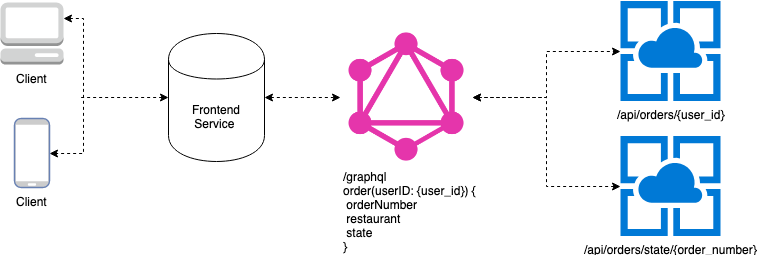
Example GraphQL Service Flow
The front-end service would only have to query the GraphQL service. The GraphQL service would then have resolvers to query the two separate RESTful services and resolve and return the data that the front end asked for. Nothing more, nothing less.
By Aaron Welsh, Software Developer
Own your marketing data & simplify your tech stack.
Have you read?

I have worked in SEO for 12+ years and I’ve seen the landscape shift a dozen times over. But the rollout of generative search engines (GSEs) feels like the biggest...

As you will have likely seen, last week Google released the March 2024 Core Algorithm Update. With it, comes a host of changes aiming to improve the quality of ranking...

After a year of seemingly constant Google core updates and the increasingly widespread usage of AI, the SEO landscape is changing more quickly than ever. With this rapid pace of...